ArkoseLabs FunCaptcha 协议逆向与风控要点
虽然这一期还是有手就行,但考虑到有点费手,就没加入《有手系列》里,我知道很贴心,不用谢~ 让我们直接进入正题!
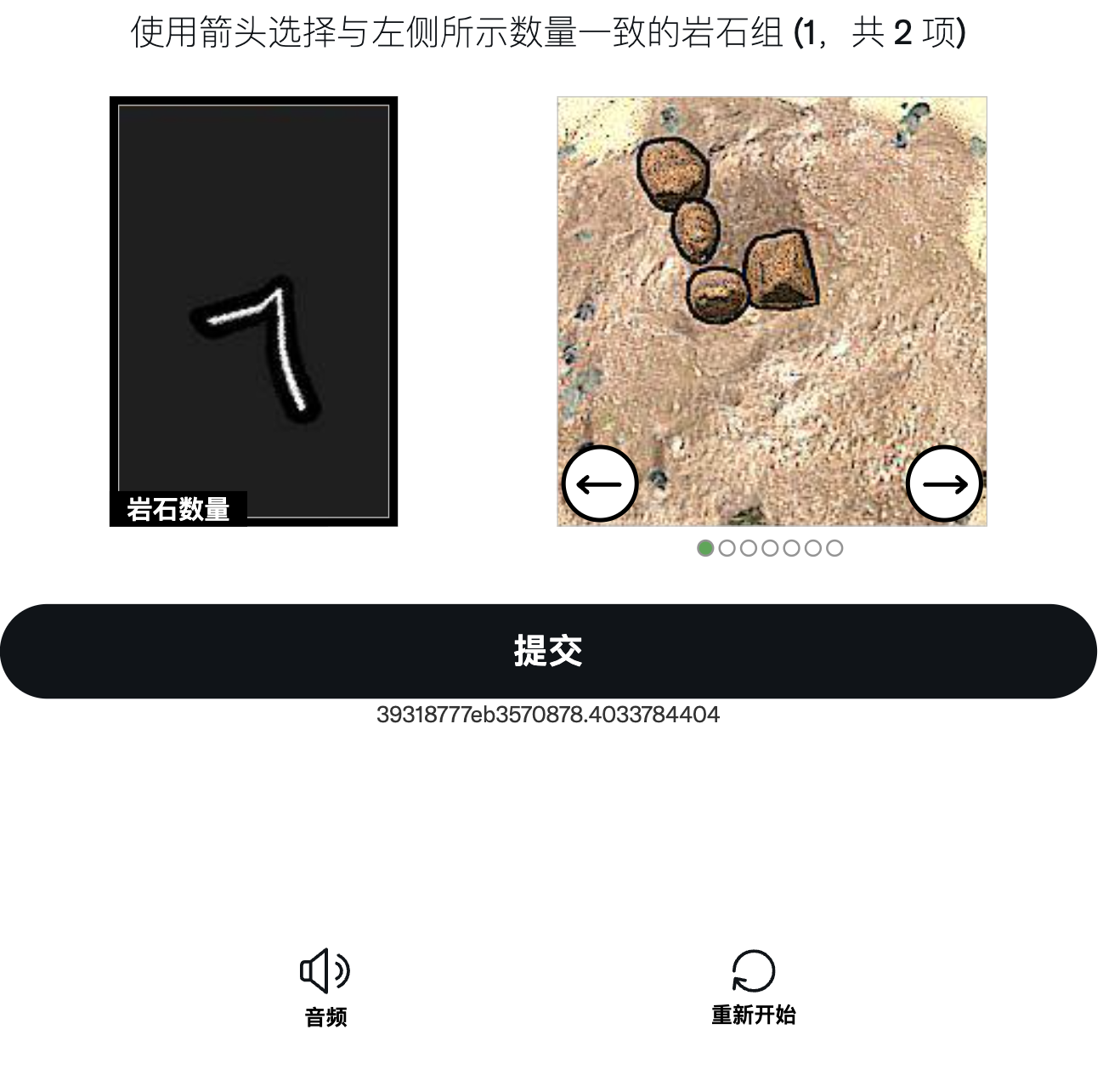
相信大家对这个验证码并不陌生,以下是FunCaptcha的一个例子。如果你的环境足够干净,没有被风控的话,做的题目会很少,以及选项中的可切换答案图片(对应难度)也会很少,接下来我会详细说明相关的内容
一、完整的请求链路
这一章节,主要梳理下完整的验证请求链接,整个验证中涉及到的请求链路,下一章节将详细介绍请求里涉及到的参数和返回结果的解析。
整体流程如下:
1、获取session token
POST https://client-api.arkoselabs.com/fc/gt2/public_key/{对应的public-key}

这一步至关重要,这一步提交的data涉及到你的设备指纹信息,将决定后续你是否需要pow验证,以及相关的验证码难度和数量等。如果构造的设备指纹或请求指纹太劣质,甚至将会被直接拒绝返回 {"error":"DENIED ACCESS"},或者在步骤3时直接返回 {"error":"DENIED ACCESS"}。这一步需要重点关注的是response里的token 字段分隔符 | 第一个值即为token,这里是 26318777fbd628c58.1761804104 ,这个token将贯穿整个验证流程。cdn里的js代码是动态变化的,这一点和CloudFlare类似。
2、【Optional】Pow挑战,如果步骤一中返回结果中需要pow挑战,需要先进行pow挑战,并提交相关结果给服务器,根据返回结果
3、获取/刷新验证码详情
POST https://client-api.arkoselabs.com/fc/gfct/

如需验证码挑战则这一步请求会返回相应的验证码详情。这一步需要注意的是response里的 challengeID 和 _challenge_imgs 里当前验证码的图片。再次请求该接口会刷新当前的验证码
4、提交当前验证码结果
POST https://client-api.arkoselabs.com/fc/ca/
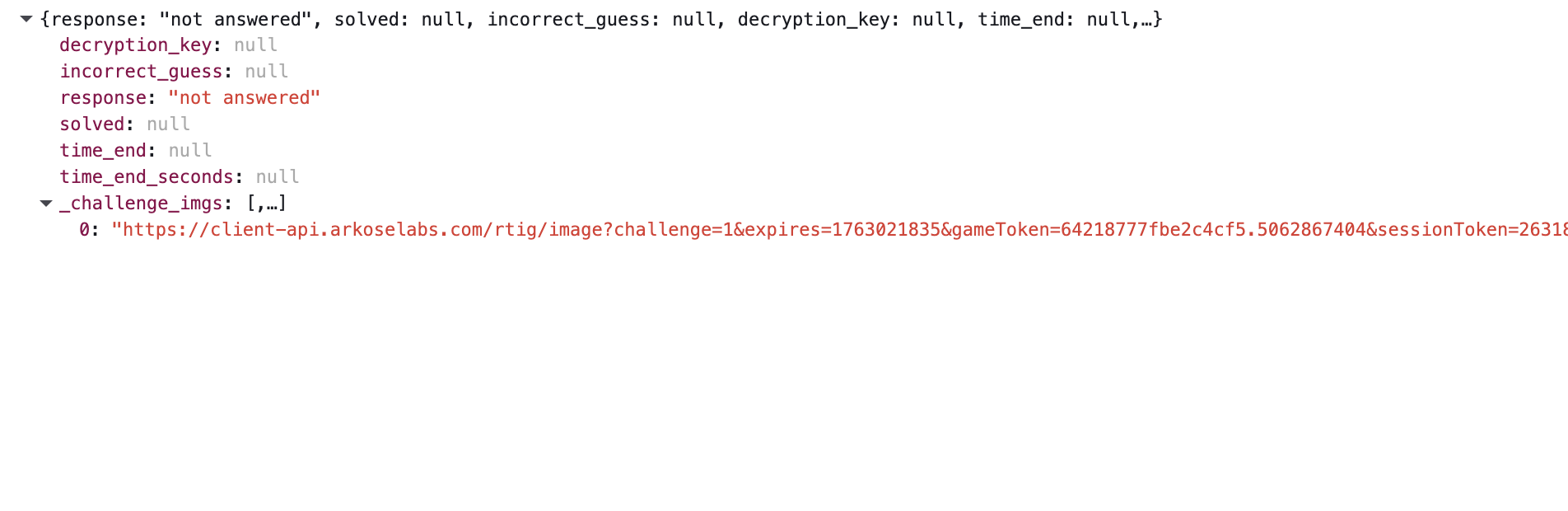
这一步提交后,如果未完成所有的验证的话,则response为not answered ,_challenge_imgs 是下一张验证码的图片地址。如果当前是最后一张验证码,通过验证后是 response 字段为 answered,solved 为 true ,反之则是 false ,中间有问题回答错了。这一步实则是链式地提交验证码结果,直到所有的验证码都提交答案了,才会得知最终是否通过了验证
二、相关请求参数和结果的详细解析
OK,让我们潜入!这一趴才是真正的重点主题,我将详细的剖析具体每个请求里的参数来源及构成,至于 response 里需要关注的重点字段,上一章节里已提及,这一章就不再赘述了!
1、获取Session Token
POST https://client-api.arkoselabs.com/fc/gt2/public_key/{对应的public-key}
需要关注的参数:
-
header里的参数,x-ark-esync-value
- url里的public key,每个站点的具体网页(同一个站点,但不同业务场景)都不一样
- 请求动态参数,c、userbrowser(请求头UA,与设备指纹一致)、rnd(随机数)
- 固定参数,style_theme、capi_mode、public_key、site,直接与网页里的结果固定就好
- data[blob],这个参数单独拎出来,是因为这个参数是网页后端返回传的,如果网站没传的话,值为
undefined
关于请求头里的 x-ark-esync-value 参数,直接参考下面这个构造函数即可:
import time
from typing import Optional
def arkose_esync_timestamp(ms: Optional[int] = None) -> int:
"""
复现时间戳计算。
:param ms: 可选的毫秒级时间戳;不传则使用当前时间。
:return: 向下取整到 21600ms 的时间戳。
"""
ALIGNMENT_MS = 21600 # 与脚本中的 b.Jy 相同
current = ms if ms is not None else int(time.time() * 1000)
return round(current - current % ALIGNMENT_MS)
这一步请求其实重中之重是 c 参数,也就是旧版的 bda 参数,c的参数的来源其实是将收集到的设备指纹进行混合加密(对称加密 + 非对称加密),具体流程如下
a. 数据预处理
- 将收集到的设备信息JSON序列化为字节流
b. 对称加密(AES-256-GCM)
- 随机生成32字节AES密钥和12字节IV(初始化向量,实现每次加密都是全新的密钥和IV)
- 使用AES-GCM模式加密数据,产生密文和认证标签(tag)
- GCM模式提供加密+完整性校验
c. 非对称加密(RSA-OAEP)
- 用RSA公钥加密AES密钥
- 解决密钥传输问题:只有持有RSA私钥的服务端能解密
4. 组装最终密文
- 按顺序Base64编码这几个字段
IV、Tag、加密后的密钥、密文 - 将分别编码后的字段直接拼接在一起
可参考以下构造函数,Public Key不一样,所对应的 RSA 密钥也都不一样
def rsa_encrypt_arkose(fp_data: dict):
"""
Arkose Labs 加密
Args:
data: 字典或字符串
"""
# 1. 序列化数据
if isinstance(fp_data, (dict, list)):
plaintext = json.dumps(data, separators=(',', ':')).encode()
else:
plaintext = fp_data.encode() if isinstance(fp_data, str) else fp_data
# 2. 生成随机密钥
aes_key = get_random_bytes(32)
iv = get_random_bytes(12)
# 3. AES-GCM 加密
cipher = AES.new(aes_key, AES.MODE_GCM, nonce=iv)
ciphertext, tag = cipher.encrypt_and_digest(plaintext)
# 4. RSA 加密密钥
rsa_key = RSA.import_key(PUBLIC_KEY_PEM)
rsa_cipher = PKCS1_OAEP.new(rsa_key)
encrypted_key = rsa_cipher.encrypt(aes_key)
iv_b64 = base64.b64encode(iv).decode()
tag_b64 = base64.b64encode(tag).decode()
key_b64 = base64.b64encode(encrypted_key).decode()
cipher_b64 = base64.b64encode(ciphertext).decode()
result = f"{iv_b64}{tag_b64}{key_b64}{cipher_b64}"
return result
这也就意味着 AES 的密钥是经过 RSA 加密后的,也就无法直接从 c 字段里拿到的数据直接base64解码拿到密钥明文。如果对设备指纹明文感兴趣的话,可以在 api.js 文件 (https://client-api.arkoselabs.com/v2/{替换为为对应的public-key}/api.js) 里搜索 bda 关键词,找到位于case 21: 的位置,往上找到 case 9: 位置的 Cn(r, Fo, Do.publicKey, si); 即该分支的最后一个函数调用,第一个 参数 r 即为设备指纹原文数组,如下图所示:
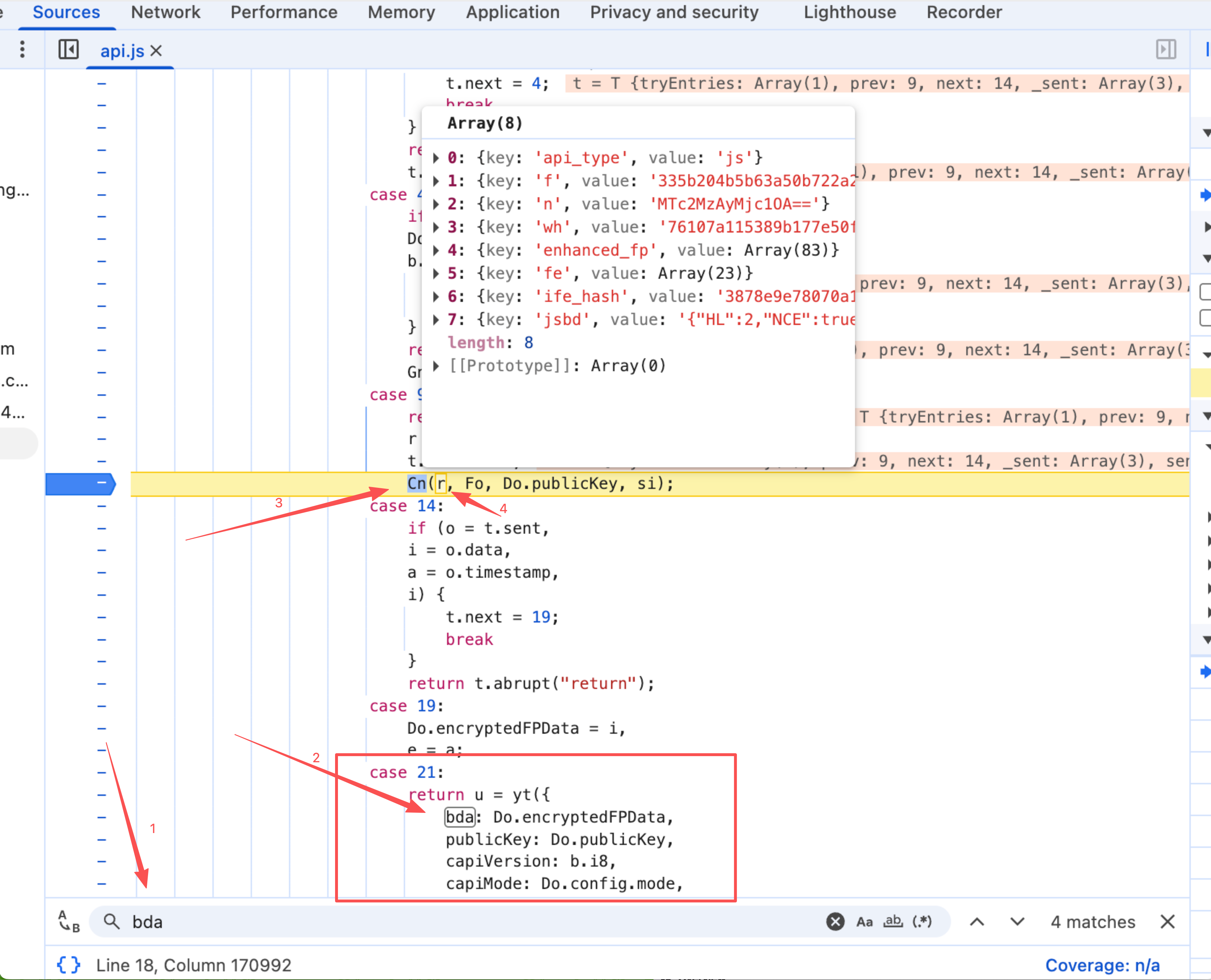
至于里面具体的设备指纹都涉及哪些,我就不细细展开了,可以参考这个网站:https://azureflow.github.io/arkose-fp-docs/arkose_re_docs.html ,里面有详细的每个参数的介绍和构造原理。还需要注意的一点是请求时候的请求指纹——JA3、Akamai指纹,这也是风控中很重要的一环!
注意!!!这一步的请求极其重要,携带的设备指纹,以及请求的IP、指纹,将直接决定后续是否需要进行POW挑战,以及验证码的难度(题目数据、题目难度)!
2、 获取/刷新验证码详情
POST https://client-api.arkoselabs.com/fc/gfct/
这一步没有涉及任何复杂的加密,仅仅是一个时间戳需要简单构造一下,相关请求的参数如下:
-
请求头, x-newrelic-timestamp(实测不携带也不会有影响)
- 可变参数,token(第一步response有返回)、sid(第一步response有返回)
- 固定参数,lang、render_type、isAudioGame、is_compatibility_mode、apiBreakerVersion、analytics_tier,都是固定值,保持和网页端同步即可
请求头参数 x-newrelic-timestamp 直接参考以下 Python 代码即可,拿走不谢~
def generate_timestamp_string():
timestamp_ms = int(datetime.now().timestamp() * 1000)
timestamp_str = str(timestamp_ms)
x = timestamp_str[:7]
l = timestamp_str[7:13]
return f"{x}00{l}"
3、提交验证码详情
POST https://client-api.arkoselabs.com/fc/ca/
又一个重头戏来咯!需要注意的请求参数:
- 请求头, x-newrelic-timestamp(相关构造请参考步骤2)、x-requested-id(需构造加密)
- 固定参数:render_type、analytics_tier、is_compatibility_mode
- 可变参数:session_token(请求1中返回)、game_token(请求2中的)、guess(与回答验证码答案有关,需构造加密)、tguess(同guess,但参数不一样)、bio(Base64解码可见,与用户交互相关)
其实这个请求所涉及的加密都使用的标准的 AES-CBC,但里面的细节会有点说法,总的加密流程如下,分为三个关键步骤:
a.密钥派生 (EVP_BytesToKey)
- 输入: session token(字符串) + 随机盐(8字节)
- 过程:使用 OpenSSL 的 EVP_BytesToKey 算法,通过多轮 MD5 哈希迭代生成足够长度的材料
- 输出: 32字节密钥 + 16字节初始化向量(IV)
b. 数据填充与加密
- 填充: 使用 PKCS7 标准,将明文补齐到16字节的整数倍
- 加密: AES-256-CBC 模式,使用派生的密钥和IV进行加密
c. 结果封装
返回 CryptoJS 标准格式的 JSON:
{
"ct": "密文的Base64编码",
"iv": "初始化向量的16进制",
"s": "盐值的16进制"
}
注:也就意味着每次加密都生成新的随机盐,即使相同明文和密码,密文也不同
我知道看的很头大,直接参考下面的 Python 程序即可:
# pip install pycryptodome
import base64
import json
from Crypto.Cipher import AES
from Crypto.Random import get_random_bytes
from Crypto.Hash import MD5
def evp_bytes_to_key(token, salt, key_len=32, iv_len=16):
"""
CryptoJS的OpenSSL兼容密钥派生 (EVP_BytesToKey)
"""
m = []
i = 0
while len(b''.join(m)) < (key_len + iv_len):
md5 = MD5.new()
data = token.encode() + salt
if i > 0:
data = m[i - 1] + data
md5.update(data)
m.append(md5.digest())
i += 1
ms = b''.join(m)
return ms[:key_len], ms[key_len:key_len + iv_len]
def encrypt(plaintext: str, token: str):
"""
模拟CryptoJS的AES.encrypt
"""
# 生成随机salt (8字节)
salt = get_random_bytes(8)
# 派生key和iv
key, iv = evp_bytes_to_key(token, salt)
# AES-256-CBC加密
cipher = AES.new(key, AES.MODE_CBC, iv)
# Pkcs7填充
pad_len = 16 - len(plaintext) % 16
padded = plaintext.encode() + bytes([pad_len] * pad_len)
# 加密
ciphertext = cipher.encrypt(padded)
# 返回CryptoJS格式
return json.dumps({
"ct": base64.b64encode(ciphertext).decode(),
"iv": iv.hex(),
"s": salt.hex()
})
def decrypt(encrypted_json: str, token: str):
"""
模拟CryptoJS的AES.decrypt
"""
data = json.loads(encrypted_json)
# 解析参数
ciphertext = base64.b64decode(data['ct'])
iv = bytes.fromhex(data['iv'])
salt = bytes.fromhex(data['s'])
# 派生key和iv
key, _ = evp_bytes_to_key(token, salt)
# AES-256-CBC解密
cipher = AES.new(key, AES.MODE_CBC, iv)
plaintext = cipher.decrypt(ciphertext)
# 去除Pkcs7填充
pad_len = plaintext[-1]
return plaintext[:-pad_len].decode()
关于 guess 和 tguess ,逻辑都是一样的,token 参数都是对应的session token(请求1中获取的结果),就可以对请求参数进行解密了,guess对应的明文为 [{"index":0},{"index":2}] 1和2为对应每轮验证码的图片答案下标。至于 tguess 结构和 guess 一致,但是里面的参数没有这么标准,每次验证请求的js文件不一样,导致 tguess 参数构造的明文也不一样,具体可以多解密几个请求中的 tguess 参数看看。
至于请求头中的 x-requested-id ,使用的加密手段和 guess、tguess 一致,只不过密钥(Python参考代码中 token 参数)不再是单纯的 session token,而是 REQUESTED{token}ID 这样的拼接结果,同样,和 tguess 一样,每次验证的时候明文都会不一样,类似 {"sc":[376,345]} 这样的明文。
至于整个流程,及相关的所有参数,到这就介绍完了!容我先上个厕所,接下来,我们再讲一讲里面风控需要续哟注意的点。
三、关于风控需注意的一些点
这里所提及的风控,其实主要是针对第一步请求中获取session token至关重要,决定了你接下来的每一步是否能够正常走完流程,完成验证,而不是每一步都惨遭 {"error":"DENIED ACCESS"} 无情拒绝!
这里只是浅浅地提一下,因为能关注到这一步的,也无须我多言了,在这我抛砖引玉一下
-
构造真实的设备指纹,相关的具体每个指纹细节可参考 https://azureflow.github.io/arkose-fp-docs/arkose_re_docs.html (如上文所述)
- 所有请求的指纹与设备指纹保持一致,所有UA都保持一致
- 千万不要忽略 TLS指纹!使用真实的请求指纹,以 Akamai 指纹为标准,具体的指纹生成可参考 https://tls.browserleaks.com/json 在线查看
- 尽可能模拟自己是一个真实用户,细心观察网站里面收集的交互信息和日志上传时机及数据,耐心试探风控能够忍耐的下限,或只和其相关的关键接口交互,不浪费任何一个请求资源
注:我知道你肯定会有疑惑,那么真实的设备指纹和请求指纹哪来呢,我只能说:仁者见仁,智者见智。
四、成果展示
OK!让我们进入最令人血脉喷张的时刻!噼里啪啦说这么一堆,要是实际检验一下发现没用,那不纯纯浪费我们各自的时间,不仅是你的,还有我的,纯纯就是浪费!
好了,不发表感言废话了,让我们直接连贯开始(我这里就直接手动打码,后续可以接一个自动化打码,这里推荐我自用的 YesCaptcha, 我发誓这不是广子,虽然我真的希望是,如果品牌方看到,希望你能懂这是个人情社会 bushi…对不起我又废话了)!开始潜入!看图即可
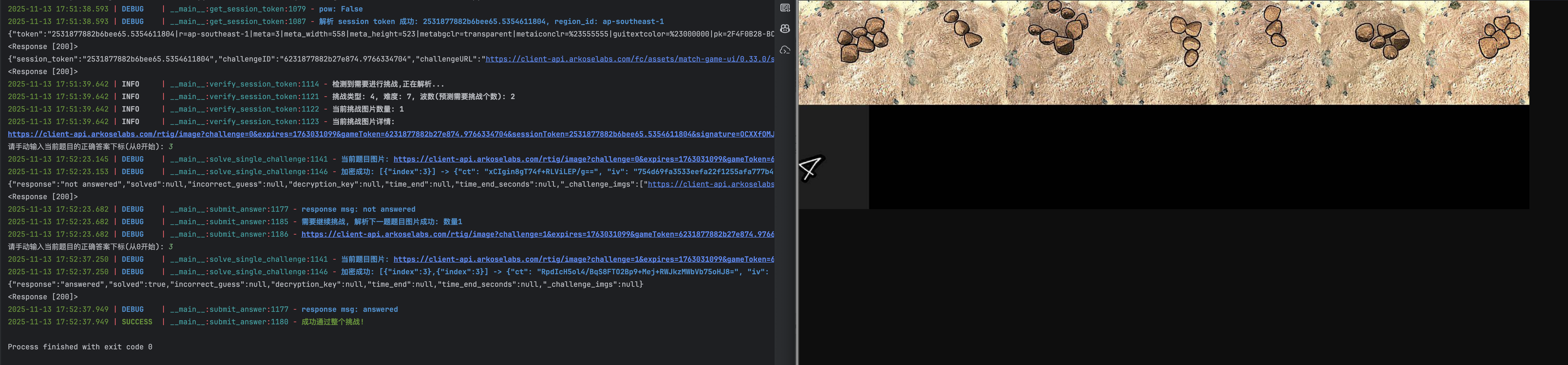
完结,散会!
版权与免责声明
- 作者: White · © 2025
- 本文仅供学习研究,禁止用于非法用途。转载须注明作者及原文链接。
- 代码部分采用 MIT 许可证 (https://opensource.org/licenses/MIT),文字部分保留所有权利
- 作者对任何阅读、转载、使用本文内容所产生的后果不承担责任。